Aesthetic Post-Training Diffusion Models from Generic Preferences with Step-by-step Preference Optimization
CVPR 2025




















Abstract
Generating visually appealing images is fundamental to modern text-to-image generation models. A potential solution to better aesthetics is direct preference optimization (DPO), which has been applied to diffusion models to improve general image quality including prompt alignment and aesthetics. Popular DPO methods propagate preference labels from clean image pairs to all the intermediate steps along the two generation trajectories. However, preference labels provided in existing datasets are blended with layout and aesthetic opinions, which would disagree with aesthetic preference. Even if aesthetic labels were provided (at substantial cost), it would be hard for the two-trajectory methods to capture nuanced visual differences at different steps.
To improve aesthetics economically, this paper uses existing generic preference data and introduces step-by-step preference optimization (SPO) that discards the propagation strategy and allows fine-grained image details to be assessed. Specifically, at each denoising step, we 1) sample a pool of candidates by denoising from a shared noise latent, 2) use a step-aware preference model to find a suitable win-lose pair to supervise the diffusion model, and 3) randomly select one from the pool to initialize the next denoising step. This strategy ensures that diffusion models focus on the subtle, fine-grained visual differences instead of layout aspect. We find that aesthetics can be significantly enhanced by accumulating these improved minor differences.
When fine-tuning Stable Diffusion v1.5 and SDXL, SPO yields significant improvements in aesthetics compared with existing DPO methods while not sacrificing image-text alignment compared with vanilla models. Moreover, SPO converges much faster than DPO methods due to the use of more correct preference labels provided by the step-aware preference model. Code and models are available at https://github.com/RockeyCoss/SPO.
Method Overview
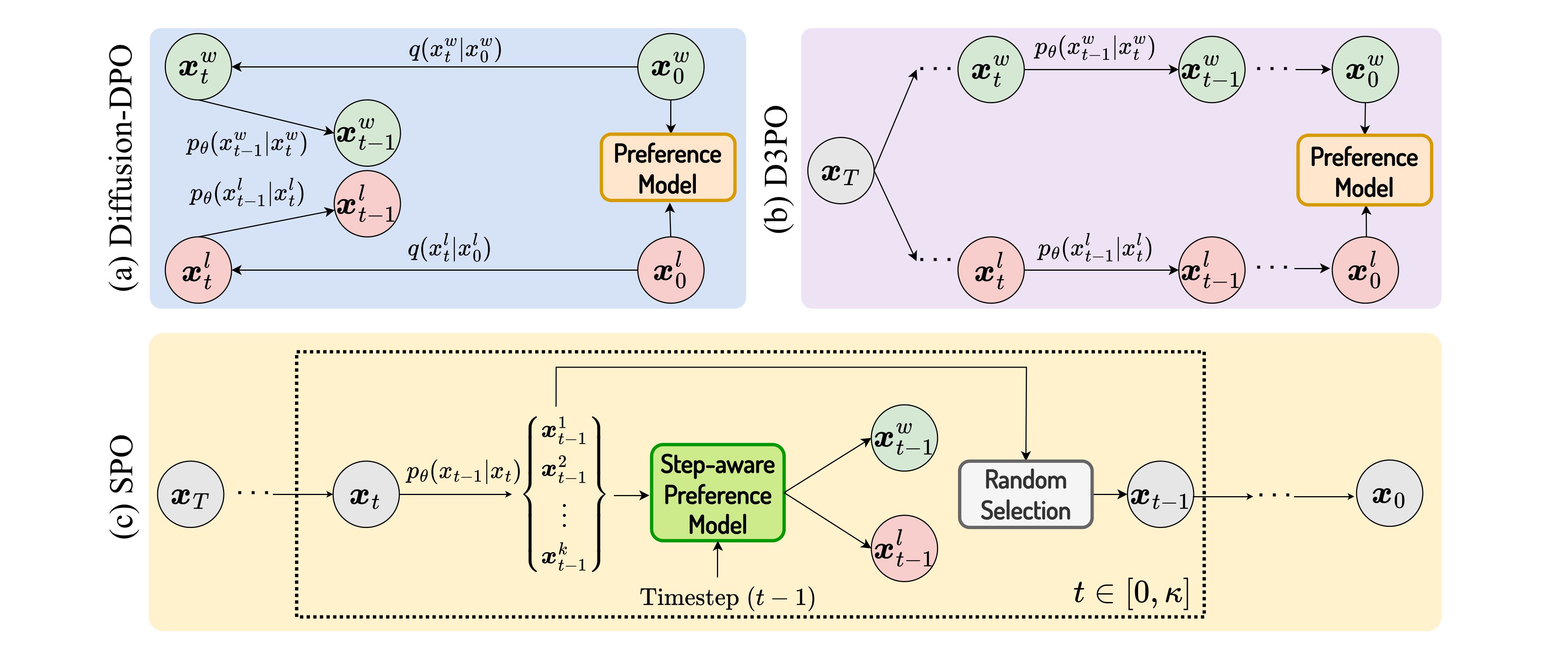
Quantitative Results
| Method | PickScore | HPSV2 | ImageReward | Aesthetic |
|---|---|---|---|---|
| SDXL | 21.95 | 26.95 | 0.5380 | 5.950 |
| Diff.-DPO | 22.64 | 29.31 | 0.9436 | 6.015 |
| SPO | 23.06 | 31.80 | 1.0803 | 6.364 |
| Method | PickScore | HPSV2 | ImageReward | Aesthetic |
|---|---|---|---|---|
| SD-1.5 | 20.53 | 23.79 | -0.1628 | 5.365 |
| DDPO | 21.06 | 24.91 | 0.0817 | 5.591 |
| D3PO | 20.76 | 23.97 | -0.1235 | 5.527 |
| Diff.-DPO | 20.98 | 25.05 | 0.1115 | 5.505 |
| SPO | 21.43 | 26.45 | 0.1712 | 5.887 |


Qualitative Results


More Visual Results












BibTeX
@article{liang2024step,
title={Aesthetic Post-Training Diffusion Models from Generic Preferences with Step-by-step Preference Optimization},
author={Liang, Zhanhao and Yuan, Yuhui and Gu, Shuyang and Chen, Bohan and Hang, Tiankai and Cheng, Mingxi and Li, Ji and Zheng, Liang},
journal={arXiv preprint arXiv:2406.04314},
year={2024}
}